シミュレーションソフトウェアの高速化・高機能化
事例 - 計算時間の短縮 - 既存コードの高速化・並列化
| 熱流体解析プログラムの高速化および大規模モデル対応(電機メーカー様) |
| 地震時応答解析ソルバの高速化(建設コンサルタント会社様) |
| 構造解析ソルバのコード整理と大規模並列行列ソルバ導入による高速化(建築メーカー様) |
| DEM法ソルバのOpenMP並列による高速化(鉄鋼メーカー様) |
熱流体解析プログラムの高速化および大規模モデル対応(電機メーカー様)
対象プログラム
内製の熱流体解析プログラム。モデルの入力はSTL。解析のアルゴリズムはIB(Immersed boundary)法を採用。すでにOpenMPによるスレッド並列化は実施済み。
目的
詳細な現象解析が実施できるように、大規模なモデルを解析したい。分散メモリ(MPI)並列化を行うことで、PCクラスタを用いてプログラムの高速化と大規模モデル化を実現したい。
実施内容1:プログラムの分析
並列化の実施に先立ち、メモリ分散と高速化の両立が可能か分析を行いました。全体の約95%を占めている処理が存在することが判明し、この部分を並列化することで、高速化は十分に可能であると判断しました。ただし、この部分の並列化軸はSTLであるため、各プロセスのメモリ使用量の平準化を実現するには、別途、空間格子のメモリ分散の手法の検討が必要。
実施内容2:MPI並列化の設計および実装
各プロセスの使用メモリが平準化され、またMPI-OpenMPのハイブリッド並列による高速化が十分に発揮できるように設計を行いました。
- ・各プロセスが担当するSTLが近い空間に集まるようにSTLを座標順に並べ替えました。
- ・解析の途中で時間刻みを変更するサブルーチンをソルバに適用し、解析時間の短縮(14%減)を実現しました。
- ・OpenMPによるスレッド並列のループ長が短くならないようにループの順番を入れ替えました。
- ・STLが存在しない領域の空間メッシュを各プロセスに割り振ることで、使用メモリと演算量の平準化を実現しました。
分散並列化の効果
20プロセス並列(20プロセス×8コア=160コア)の場合に、オリジナルコード(8コア)時の21倍の高速化を実現しました。
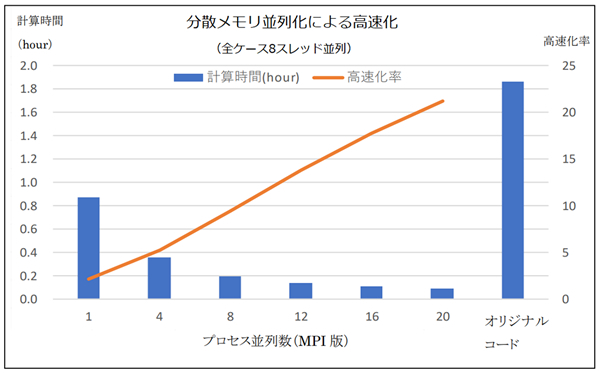
▲ 使用計算機:FOCUSスパコン Zシステム
(CPU: Intel Xeon Gold 6230、40コア/ノード、メモリ:192GB/ノード )
(注)MPI版は1プロセスの時に、オリジナルコードの2倍以上の速度向上となっています。MPI化に当たって実施した、1.解析対象モデル形状のSTLを座標順に並べ替える、2.ループの順番を入れ替える、3.余分なメモリ確保を行わない、といった修正が影響しているものと推察しますが、具体的な要因の特定は行っていません。
地震時応答解析ソルバの高速化(建設コンサルタント会社様)
- ・約1万要素の動解析を実施するのに約33時間かかっていたところを、4並列で16時間22分(50%減)の時間で計算できるようになりました。
- ・解析の途中で時間刻みを変更するサブルーチン をソルバに適用し、解析時間の短縮(14%減)を実現しました。
- ・線形ソルバをオリジナルのSkyline法から当社製 のSMS-MFに置き換えて計算時間を短縮(22%減)しました。
- ・OpenMP対応の剛性行列作成サブルーチンをソルバに適用することで高速化を 実現しました。
構造解析ソルバのコード整理と大規模並列行列ソルバ導入による高速化(建築メーカー様)
- ・主要な未並列化サブルーチンのOpenMP並列化を実施しました。
- ・Fortran77形式からFortran90形式へのコーディング変更することで、プログラムのミスを発見しやすくし、バグの修正を容易にしました。
- ・並列数によって結果に差が出る不具合の原因を特定し修正を行いました。
- ・反復法線形ソルバライブラリLis(*1)を導入し、オリジナルコード(直接法ライブラリ)と比べて、24スレッドで4.7倍の高速化を実現しました。
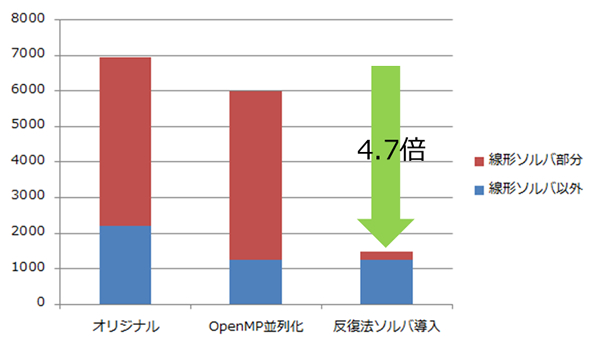
(*1) Lis:Library of Iterative Solvers for linear systems。修正BSDライセンスで公開されている線形ソルバライブラリ
http://www.ssisc.org/lis/ より入手可能。
DEM法ソルバのOpenMP並列による高速化(鉄鋼メーカー様)
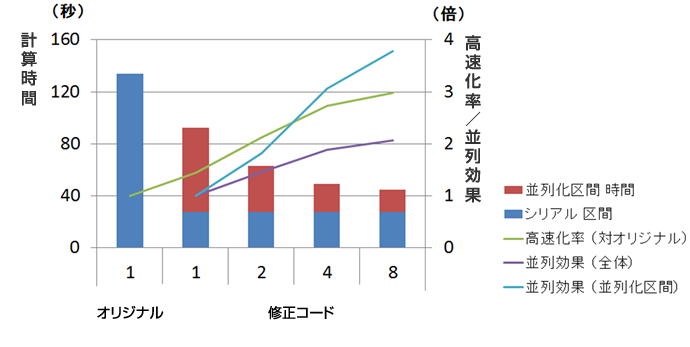
分析ツールにより、並列化の可否を調査しました。
ホットスポット部分のアルゴリズムがスレッド並列化に向かない構造であったため、計算順序を変更してスレッド並列化を可能にしました。また、この結果、シリアル計算の時間も短縮することができました。
8スレッドでの解析時に、スレッド並列区間のみではシリアル実行時の3.8倍、解析全体の速度でもオリジナルコードと比較して3倍を達成しました。
事例 - 計算時間の短縮 - マトリクスソルバ性能向上
| 代数的マルチグリッド(AMG)ソルバの並列化(宇宙航空研究開発機構(JAXA)様) |
| G方程式燃焼モデルソルバへのSMS-AMGの取組(海上技術安全研究所(NMRI)様) |
| 流体数値解析スキームの研究へのSMS-MFの適用(マサチューセッツ工科大学(MIT)様) |
| 電磁場解析へのSMS-BEMの適用(ミューテック様) |
代数的マルチグリッド(AMG)ソルバの並列化(宇宙航空研究開発機構(JAXA)様)
代数マルチグリッド(AMG)法を用いたマトリクスソルバは、非常に速い反復法のマトリクスソルバとして知られており、SOR法やICCG法といった古典的な解法と比較して数倍~20倍程度高速です。
AMG法は高い並列性能を実現するのは困難とされてきましたが、アルゴリズムの工夫により高い並列性能を実現しました。
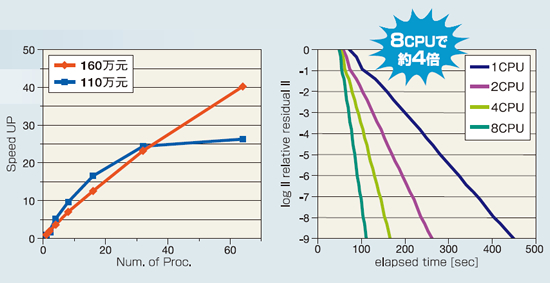
▲ (左図)並列化後のAMGソルバの並列スケーラビリティ(反復部分) / (右図)並列化後のAMGソルバの収束曲線(Strong Scaling)
G方程式燃焼モデルソルバへのSMS-AMGの取組(海上技術安全研究所(NMRI)様)
G方程式燃焼モデルに現れる圧力のポアソン方程式の求解を行うマトリクスソルバとしてSMS-AMGを適用することで、計算時間の大幅な短縮を実現しました。
マトリクスソルバ部分ではBiCGSTAB法の約4倍高速化されたため、研究効率が格段に向上しました。そのぶん計算格子数を増加させた計算が可能となり、より詳細な燃焼場解析が可能となりました。
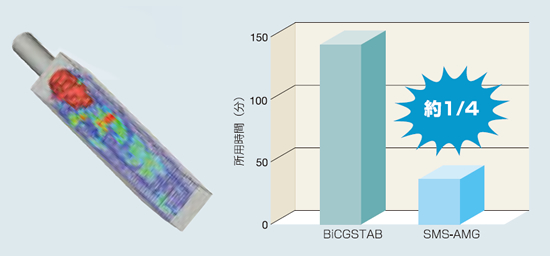
▲ (左図)燃焼室内の流れの速度-ベクトルと火炎面(瞬時値) / (右図)SMS-AMGによる高速化効果
流体数値解析スキームの研究へのSMS-MFの適用(マサチューセッツ工科大学(MIT)様)
FCIB(Flow-Condition-Based Interpolation)法と呼ばれる有限要素法による流体数値解析スキームの研究では、連立一次方程式の計算に直接法しか用いることができず、計算に時間がかかり、かつメモリの制限を受けるため大規模な計算ができない、という問題がありました。SMS-MFを適用することで、15万元の問題を1GBメモリで計算可能となり、計算時間も数日かかっていた計算が5分で求解できるようになりました。
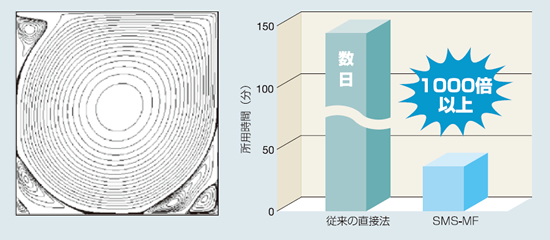
▲ (左図)正方形Cavity内の二次元定常非圧縮粘性流れ計算例(流線) / (右図)SMS-MFによる高速化効果
電磁場解析へのSMS-BEMの適用(ミューテック様)
電磁場解析で現れる境界要素法のマトリクスソルバとしてSMS-BEMを適用し、10倍~20倍の高速化を実現しました。
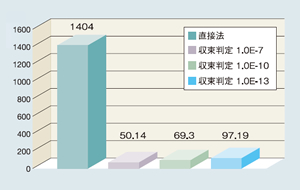
▲ SMS-BEMによる高速化効果
シミュレーションソフトウェアの高速化・高機能化を支援するツールのご紹介
Super Matrix Solver 高速・高安定型マトリクスソルバライブラリ
Super Matrix Solver(スーパーマトリクスソルバ)は連立一次方程式求解用のソフトウェアライブラリです。熱流体解析や構造解析などの数値計算で用いられる連立一次方程式の求解計算を高速かつ安定的に実行することを目的として、宇宙航空研究開発機構(JAXA)で開発された基礎理論をベースにヴァイナスにより開発された製品です。
大規模かつ求解の困難な連立一次方程式を高精度かつ短時間で安定的に解くことができます。反復法・直接法・境界要素法専用ソルバなど複数の製品で構成されており、様々な分野でご利用可能です。

![]()
